
Урок №17.
Обработка данных
Статистическая обработка массивов
Сортировка элементов массивов
Триангуляция
Преобразования Фурье
Свертка и обратная ей операция
Дискретная фильтрация
Аппроксимация и интерполяция
Обработка данных в окне графики
Этот урок посвящен традиционной обработке данных. В нем приведены основные функции для обработки данных, представленных массивами. Они широко используются для анализа данных физических, химических, экономических и иных экспериментов. Это большой урок, рассчитанный на разбиение его на части или выборочное изучение. Последнее более предпочтительно, поскольку урок охватывает данную тему достаточно широко.
Статистическая обработка данных
Нахождение максимального и минимального элементов массива
Самый простой анализ данных, содержащихся в некотором массиве, заключается в поиске его элементов с максимальным и минимальным значениями. В системе MATLAB определены следующие быстрые функции для нахождения минимальных и максимальных элементов массива:
mах(А) — возвращает наибольший элемент, если А — вектор; или возвращает вектор-строку, содержащую максимальные элементы каждого столбца, если А — матрица, в многомерных массивах работает с первой не единичной размерности;
mах(А.В) — возвращает массив того же размера, что А и В, каждый элемент которого есть максимальный из соответствующих элементов этих массивов;
max(A.[ ],dim) — возвращает наибольшие элементы по столбцам или по строкам матрицы в зависимости от значения скаляра dim. Например, тах(А,[ ],1) возвращает максимальные элементы каждого столбца матрицы А;
[C.I] =max(A) — кроме максимальных значений возвращает вектор индексов I этих элементов.
Примеры:
» A=magic(7)
|
30 |
39 |
48 |
1 |
10 |
19 |
28 |
|
38 |
47 |
7 |
9 |
18 |
27 |
29 |
|
46 |
6 |
8 |
17 |
26 |
35 |
37 |
|
5 |
14 |
16 |
25 |
34 |
36 |
45 |
|
13 |
15 |
24 |
33 |
42 |
44 |
4 |
|
21 |
23 |
32 |
41 |
43 |
3 |
12 |
|
22 |
31 |
40 |
49 |
2 |
11 |
20 |
» С = max(A)
С=
46 47 48 49 43 44 45
» С = max(A.[ ].l)
С =
46 47 48 49 43 44 45
» С = max(A.[ ],2)
С =
48
47
46
45
44
43
49
»[C,I]=max(A)
C=
49 43 44 45
I=
7 6 5 4
Для быстрого нахождения элемента массива с минимальным значением служит следующая функция:
min(A) — возвращает минимальный элемент, если А — вектор; или возвращает вектор-строку, содержащую минимальные элементы каждого столбца, если А — матрица;
min(A.B) — возвращает массив того же размера, что А и В, каждый элемент которого есть минимальный из соответствующих элементов этих массивов;
min(A,[ ],dim) — возвращает наименьший элемент по столбцам или по строкам матрицы в зависимости от значения скаляра dim. Например, тах(А,[ ],1) возвращает минимальные элементы каждого столбца матрицы А;
[C,I] = min(A) — кроме минимальных значений возвращает вектор индексов этих элементов.
Пример:
» A=magic(4)
А =
16 2 3 13
5 11 10 8
9 7 6 12
4 14 15 1
» [C.I] = min(A)
C =
4 2 3 1
I =
4 1 1 4
Работа указанных функций базируется на сравнении численных значений элементов массива А, что и обеспечивает высокую скорость выполнения операций.
Нахождение средних, срединных значений массива и стандартных отклонений
Элементарная статистическая обработка данных в массиве обычно сводится к нахождению их среднего значения, медианы (срединного значения) и стандартного отклонения. Для этого в системе MATLAB определены следующие функции:
mean (А) — возвращает арифметическое среднее значение элементов массива, если А — вектор; или возвращает вектор-строку, содержащую средние значения элементов каждого столбца, если А — матрица. Арифметическое среднее значение есть сумма элементов массива, деленная на их число;
mean(A.dim) — возвращает среднее значение элементов по столбцам или по строкам матрицы в зависимости от значения скаляра dim (dim=l по столбцам и dim=2 по строкам соответственно).
Примеры:
|
» А = [1 |
2 6 4 |
8; 6 7 |
13 5 4; |
7 9 0] |
|
А = |
|
|
|
|
|
1 |
2 |
6 |
4 |
8 |
|
6 |
7 |
13 |
5 |
4 |
|
7 |
9 |
0 |
8 |
12 |
|
6 |
6 |
7 |
1 |
2 |
|
» mean(A) |
|
|
|
|
|
ans = |
|
|
|
|
|
5.0000 |
6.0000 |
6.5000 |
4.5000 |
6.5000 |
|
»mean(A. |
2) |
|
|
|
|
ans = |
|
|
|
|
|
4.2000 |
|
|
|
|
|
7.0000 |
|
|
|
|
|
7.2000 |
|
|
|
|
|
4.4000 |
|
|
|
|
median (A) — возвращает медиану, если А — вектор; или вектор-строку медиан для каждого столбца, если А — матрица;
median(A.dim) — возвращает значения медиан для столбцов или строк матрицы в зависимости от значения скаляра dim.
Примеры:
» A=magic(6)
|
35 |
1 |
6 |
26 |
19 |
24 |
|
3 |
32 |
7 |
21 |
23 |
25 |
|
31 |
9 |
2 |
22 |
27 |
20 |
|
8 |
28 |
33 |
17 |
10 |
15 |
|
30 |
5 |
34 |
12 |
14 |
16 |
|
4 |
36 |
29 |
13 |
18 |
11 |
» M=median(A)
М =
19.000018.500018.000019.000018.500018.0000
» M=median(A,2)
М =
21.5000
22.0000
21.0000
16.0000
15.0000
15.5000
std(X) — возвращает стандартное отклонение элементов массива, вычисляемое по формуле если X — вектор. Если X — матрица, то std(X) возвращает вектор-строку, содержащую стандартное отклонение элементов каждого столбца (обратите внимание, что оно отличается от среднеквадратического отклонения);
std(X.flag) — возвращает то же значение, что и std(X), если flag=0; если flag=l, функция std(X.l) возвращает среднеквадратическое отклонение (квадратный корень из несмещенной дисперсии), вычисляемое по формуле
std(X.flag.dim) — возвращает стандартное или среднеквадратическое отклонения по рядам (dim=2) или по столбцам(dim=1) матрицы X в зависимости от значения переменной dim.
Примеры:
» X = linspace(0,3*pi,10)
X = Columns 1 through 7
0 1.0472 2.0944 3.1416 4.1888 5.2360 6.2832
Columns 8 through 10
7.3304 8.3776 9.4248
» s = std(X)
s =
3.1705
Функции сортировки элементов массива
Многие операции статистической обработки данных выполняются быстрее и надежнее, если данные предварительно отсортированы. Кроме того, нередко представление данных в отсортированном виде более наглядно и ценно. Ряд функций служит для выполнения сортировки элементов массива. Они представлены ниже.
sort (А) — в случае одномерного массива А сортирует и возвращает элементы по возрастанию их значений; в случае двумерного массива происходит сортировка и возврат элементов каждого столбца. Допустимы вещественные, комплексные и строковые элементы. Если А принимает комплексные значения, то элементы сначала сортируются по абсолютному значению, а затем, если абсолютные значения равны, по аргументу. Если А включает NaN-элементы, sort помещает их в конец;
[В. INDEX] = sort(A) — наряду с отсортированным массивом возвращает массив индексов INDEX. Он имеет размер size(A), с помощью этого массива можно восстановить структуру исходного массива.
sort(A.dim) — для матриц сортирует элементы по столбцам (dim=l) или по рядам в зависимости от значения переменной dim.
Примеры:
|
» A=magic(5) |
|||||
|
А = |
|
|
|
|
|
|
17 |
24 |
1 |
8 |
15 |
|
|
23 |
5 |
7 |
14 |
16 |
|
|
4 |
б |
13 |
20 |
22 |
|
|
10 |
12 |
19 |
21 |
3 |
|
|
11 |
18 |
25 |
2 |
9 |
|
|
» [В. B= |
INDEX] |
sort(A) |
|
|
|
|
4 |
5 |
1 |
2 |
3 |
|
|
10 |
6 |
7 |
8 |
9 |
|
|
11 |
12 |
13 |
14 |
15 |
|
|
17 |
18 |
19 |
20 |
16 |
|
|
23 |
24 |
25 |
21 |
22 |
|
|
index= |
|
|
|
|
|
|
3 |
2 |
1 |
5 |
4 |
|
|
4 |
3 |
2 |
1 |
5 |
|
|
5 |
4 |
3 |
2 |
1 |
|
|
1 |
5 |
4 |
3 |
2 |
|
|
2 |
1 |
5 |
4 |
3 |
|
sortrows(A) — выполняет сортировку рядов массива А по возрастанию и возвращает отсортированный массив, который может быть или матрицей, или вектором-столбцом;
sortrows(A.column) — возвращает матрицу, отсортированную по столбцам, точно указанным в векторе column. Например, sortrows(A,[2 3]) сортирует строки матрицы А сначала по второму столбцу, и затем, если его элементы равны, по третьему;
[В, index] = sort rows (А) — также возвращает вектор индексов index. Если А — вектор-столбец, то B=A(index). Если А — матрица размера тхп, то B=A(index.:).
Примеры:
» А=[2 35689: 5 7 1 2 3 5:1 3 2 1 5 1:5 0 8 8 4 3]
А =
|
|
2 |
3 5 |
6 |
8 |
9 |
||
|
|
5 |
7 1 |
2 |
3 |
5 |
||
|
|
1 |
3 2 |
1 |
5 |
1 |
||
|
|
5 |
0 8 |
8 |
4 |
3 |
||
|
» |
В= |
sortrows(A) |
|
|
|
||
|
в |
= |
|
|
|
|
||
|
|
1 |
3 2 |
1 |
5 |
1 |
||
|
|
2 |
3 5 |
6 |
3 |
9 |
||
|
|
5 |
0 8 |
8 |
4 |
3 |
||
|
|
5 |
7 1 |
2 |
3 |
5 |
||
» b = sortrows(A.3)
b=
|
5 |
7 |
1 |
2 |
3 |
5 |
|
1 |
3 |
2 |
1 |
5 |
1 |
|
2 |
3 |
5 |
6 |
8 |
9 |
|
5 |
0 |
8 |
8 |
4 |
3 |
cplxpair(A) — сортирует элементы по строкам или столбцам комплексного массива А, группируя вместе комплексно сопряженные пары. Затем найденные пары сортируются по возрастанию действительной части. Внутри пары элемент с отрицательной мнимой частью является первым. Действительные элементы следуют за комплексными парами. Заданный по умолчанию порог 100*eps относительно abs(A(i))) определяет, какие числа являются действительными и какие элементы являются комплексно сопряженными. Если А — вектор, cpl xpair (А) возвращает А вместе с комплексно сопряженными парами. Если А — матрица, cpl xpai r(А) возвращает матрицу А с комплексно сопряженными парами, сортированную по столбцам;
cplxpalr(A,tol) — отменяет заданный по умолчанию порог и задает новый tol;
cplxpair(A.[].dim) — сортирует матрицу А по строкам или по столбцам в зависимости от значения параметра dim;
cplxpair(A,tol ,dim) — сортирует матрицу А по строкам или по столбцам в зависимости от значения параметра dim, используя заданный порог tol.
Пример:
» А=[23+121.34-31.45:23-121.-12.21:-3.34+31.-21]
А =
23.0000 + 12.00001 34.0000 - 3.00001 45.0000
23.0000 - 12.00001 -12.0000 0 + 2.00001
-3.0000 34.0000 + 3.00001 0 - 2.00001
» cplxpair(A)
ans =
23.0000 - 12.00001 34.0000 - 3.00001 0 - 2.00001
23.0000 + 12.00001 34.0000 + 3.00001 0 + 2.00001
-3.0000 -12.0000 45.0000
Вычисление коэффициентов корреляции
Под корреляцией понимается взаимосвязь некоторых величин, представленных данными — векторами или матрицами. Общепринятой мерой линейной корреляции является коэффициент корреляции. Его близость к единице указывает на высокую степень линейной зависимости. Данный раздел посвящен описанию функции для вычисления коэффициентов корреляции и определения ковариационной матрицы элементов массива. Приведенная ниже функция позволяет вычислить коэффициенты корреляции для входного массива данных.
corrcoef(X) — возвращает матрицу коэффициентов корреляции для входной матрицы, строки которой рассматриваются как наблюдения, а столбцы — как переменные. Матрица S=corrcoef(X) связана с матрицей ковариаций C=cov(X) следующим соотношением: S(i.j)=C(i.j)/sqrt(C(i.i)C(j.j));
Функция S = corrcoef (х,у), где х и у — векторы-столбцы, аналогична функции соггсоеЩх у]). Пример:
|
» M=magic(5) |
|||||
|
M = |
|
|
|
|
|
|
17 |
24 |
1 |
8 |
15 |
|
|
23 |
5 |
7 |
14 |
16 |
|
|
4 |
6 |
13 |
20 |
22 |
|
|
10 |
12 |
19 |
21 |
3 |
|
|
11 |
18 |
25 |
2 |
9 |
|
» S=corrcoef(M)
S =
1.0000 0.0856 -0.5455 -0.3210 -0.0238
0.0856 1.0000 -0.0981 -0.6731 -0.3210
-0.5455 -0.0981 1.0000 -0.0981 -0.5455
-0.3210 -0.6731 -0.0981 1.0000 0.0856
-0.0238 -0.3210 -0.5455 0.0856 1.0000
В целом, корреляция данных довольно низкая. В данных, расположенных по диагонали — здесь коэффициенты корреляции равны 1, — вычисляется линейная корреляция переменной со своей копией.
Приведенная далее функция позволяет вычислить матрицу ковариации для массива данных.
cov(x) — возвращает смещенную дисперсию элементов вектора х. Для матрицы, где каждая строка рассматривается как наблюдение, а каждый столбец — как переменная, cov(x) возвращает матрицу ковариации. diag(cov(x» — вектор смещенных дисперсий для каждого столбца и sqrt(diag(cov(x))) — вектор стандартных отклонений.
Функция С = cov(x.y), где х и у — векторы-столбцы одинаковой длины, равносильна функции cov([x у]).
Пример:
» D=[2 -3 6:3 6 -1:9 8 5]:C=cov(D)
С =
14.3333 16.3333 3.6667
16.3333 34.3333 -10.3333
3.6667 -10.3333 14.3333
» diag(cov(D))
ans =
14.3333
34.3333
14.3333
» sqrt(diag(cov(D)))
ans =
3.7859
5.8595
3.7859
» std(D)
ans =
3.7859 5.8595 3.7859
Далее мы рассмотрим функции геометрического анализа данных. Такой анализ не относится к достаточно распространенным средствам анализа данных, но для специалистов он представляет несомненный интерес.
Пусть есть некоторое число точек. Триангуляция Делоне — это множество линий, соединяющих каждую точку с ее ближайшими соседними точками. Диаграммой Вороного называют многоугольник, вершины которого — центры окружностей, описанных вокруг треугольников Делоне.
В системе MATLAB определены функции триангуляции Делоне, триангуляции Делоне для ближайшей точки и поиска наилучшей триангуляции. Рассмотрим функции, реализующие триангуляцию Делоне.
TRI = delaunay(x.y) — возвращает матрицу размера mх3 множества треугольников (триангуляция Делоне), такую что ни одна из точек данных, содержащиеся в векторах х и у, не попадают внутрь окружностей, проходящих через вершины треугольников. Каждая строка матрицы TRI определяет один такой треугольник и состоит из индексов векторов х и у;
TRI = delaunay('x,у.'sorted'-) — при расчетах предполагается, что точки векторов х и у отсортированы сначала по у, затем по х и двойные точки уже устранены. Пример:
» rand('state',0);
» x=rand(1.25);
» y=rand(1.25);
» TRI = delaunay(x.y);
» trimeshCTRI,x.y,zeros(size(x)))
» ax1s([0 101]); hold on;
» plot(x.y.'o')
dsearch(x.y ,TRI ,xi ,yi) — возвращает индекс точки из числа содержащихся в массивах х и у, ближайшей к точке с координатами (xi,y1), используя массив данных триангуляции TRI (триангуляция Делоне для ближайшей точки);
dsearch(x,y,TRI ,xi ,yi ,S) — делает то же, используя заранее вычисленную разреженную матрицу триангуляции S: S=sparse(TRI(: ,[1 1 2 2 3 3]), TRK: ,[2 3 1 3 1 2]).1.nxy.nxy), где nxy=prod(size(x));
tsearch(x,y.TRI,xi ,yi) — выполняет поиск наилучшей триангуляции, возвращает индексы строк матрицы триангуляции TRI для каждой точки с координатами (xi ,y1). Возвращает NaN для всех точек, находящихся вне выпуклой оболочки.
Триангуляция трехмерных и n-мерных массивов (п>=2) осуществляется при помощи функций delaunayS и delaunayn соответственно. Эти функции используют не алгоритм вычисления диаграмм Вороного, как del aunay, а алгоритм qhul 1 Национального научно-технического и исследовательского центра визуализации и вычисления геометрических структур США [В MATLAB 6.1 функции delaunay, convhull, griddata, voronoi также используют qhull. - Примеч. ред.].
Построенная по приведенному ранее примеру диаграмма представлена на рис. 17.1.
Рис. 17.1. Пример применения функции delaunay
В системе MATLAB определена функция вычисления точек выпуклой оболочки:
convhull (х,у) — возвращает индексы тех точек, задаваемых векторами х и у, которые лежат на выпуклой оболочке;
convhull(x,y,TRI) — использует триангуляцию, полученную в результате применения функции триангуляции Делоне del aunay, вместо того чтобы вычислять ее самостоятельно. Пример:
» хх=-0.8:0.03:0.8;
» уу = abstsqrt(xx));
» [х,у] = po!2cart(xx.yy);
» k = convhuTI(x.y);
» plot(x(k).y(k).'r:',x,y,'g*')

Рис. 17.2. Пример использования функции convhull
Рис. 17.2 иллюстрирует применение функции convhull для построения выпуклой оболочки. Функция convhulln вычисляет n-мерную выпуклую поверхность, основана на алгоритме qhull.
В системе MATLAB определены функции, вычисляющие площадь полигона и анализирующие нахождение точек внутри полигона. Для вычисления площади полигона используется функция polyarea:
polyarea(X.Y) — возвращает площадь полигона, заданного вершинами, находящимися в векторах X и Y. Если X и Y — матрицы одного размера, то polyarea возвращает площадь полигонов, определенных столбцами X и Y;
polyarea(X.Y.dim) — возвращает площадь полигона, заданного столбцами или строками X и Y в зависимости от значения переменной dim. Пример:
» L = linspace(0.3*pi,10);
» X= sin(L)';
» Y=cos(L)';
» А = polyarea(X.Y)
А =
3.8971
» plot(X.Y.'m')

Рис. 17.3. Область многоугольника, для которого вычислена площадь
Построенный по этому примеру многоугольник представлен на рис. 17.3. В данном примере использована функция linspace(xl.x2,N), генерирующая N точек в промежутке от x1 до х2 с последующим формированием векторов X и Y для построения многоугольника в полярной системе координат.
Анализ попадания точек внутрь полигона
Функция Inpolygon используется для анализа того, попадают ли заданные точки внутрь полигона:
IN=inpolygon(X,Y.xv.yv) — возвращает матрицу IN того же размера, что X и Y. Каждый элемент матрицы IN принимает одно из значений — 1, 0.5 или 0 — в зависимости от того, находится ли точка с координатами (X(p,q),Y(p,q)) внутри полигона, вершины которого определяются векторами xv и yv:
IN(p,q) = 1 — если то.чка (X(p.q) ,Y(p,q)) лежит внутри полигона;
IN(p,q) = 0.5 — если точка (X(p,q) ,Y(p,q)) лежит на границе полигона;
IN(p.q) = 0 — если точка (X(p.q),Y(p,q)) лежит вне полигона. Пример:
» L = linspace(0.2*pi,8);
» yv = sln(L)';
» xv - cos(L)';
» x - randn(l00.l); у = randn(l00.l);
» IN = inpolygon(x.y.xv.yv);
» plot(xv.yv.'k',x(IN),y(IN).'r*'.x(~IN).y(~IN).'bo')
Построенные в этом примере массив точек и полигон представлены на рис. 17.4.

Рис. 17.4. Пример применения функции inpolygon
Точки, попавшие внутрь полигона, обозначены символом звездочки, а точки вне полигона обозначены кружками.
Для построения диаграммы Вороного служат следующие команды:
voronoi(x.y) — строит диаграмму Вороного для точек с координатами (х,у). Функция voronoi(х,у,TRI) использует триангуляцию TRI;
voronoi (...,' LineSpec') — строит диаграмму с заданным цветом и стилем линий;
[vx.vy] = voronoi (...) — возвращает вершины граней Вороного в векторах vx и vy, так что команда plot(vx,vy,'-' ,х.у,'.') создает диаграмму Вороного.
Пример:
» rand('state'.0):
» x = randd.15): у = randd.15):
» TRI = delaunay(x.y);
» subplotd.2,1)....
» trimesh(TRI,x,y,zeros(s1ze(x))); view(2),...
» axis([0 101]); hold on;
» plot(x.y,'o');
» [vx, vy] = voronoi(x.y.TRI);
» subplot(l,2,2)....
» plot(x,y,'r+',vx,vy,'b-'),...
» axis([0 1 0 1])
Рисунок 17.5 (слева) иллюстрирует построение треугольников Делоне. На рисунке справа изображены знаками «плюс» центры окружностей, проведенных вокруг треугольников Делоне.
Функция [V,C]=voronoin(X) служит для построения диаграмм Вороного n-мерных данных. V — массив граней, С —массив клеток диаграмм. При n=2 вершины граней Вороного возвращаются в порядке смежности, при п>2 — в порядке убывания.

Рис. 17.5. Связь триангуляции Делоне с диаграммой Вороного
Разработка преобразований Фурье сыграла огромную роль в появлении и развитии ряда новых областей науки и техники. Достаточно отметить, что электротехника переменного тока, электрическая связь и радиосвязь базируются на спектральном представлении сигналов. Ряды Фурье также можно рассматривать как приближение произвольных функций (определенные ограничения в этом известны) тригонометрическими рядами бесконечной длины. При конечной длине рядов получаются наилучшие среднеквадратические приближения. MATLAB содержит функции для выполнения быстрого одномерного и двумерного быстрого дискретного преобразования Фурье. Для одномерного массива*с длиной N прямое и обратное преобразования Фурье реализуются по следующим формулам:
Прямое преобразование Фурье переводит описание сигнала (функции времени) из временной области в частотную, а обратное преобразование Фурье переводит описание сигнала из частотной области во временную. На этом основаны многочисленные методы фильтрации сигналов.
Функции одномерного прямого преобразования Фурье
В описанных ниже функциях реализован особый метод быстрого преобразования Фурье — Fast Fourier Transform (FFT, или БПФ), позволяющий резко уменьшить число арифметических операций в ходе приведенных выше преобразований. Он особенно эффективен, если число обрабатываемых элементов (отсчетов) составляет 2т, где т — целое положительное число. Используется следующая функция:
fft(X) — возвращает для вектора X дискретное преобразование Фурье, по возможности используя алгоритм быстрого преобразования Фурье. Если X — матрица, функция fft возвращает преобразование Фурье для каждого столбца матрицы;
fft(X.n) — возвращает n-точечное преобразование Фурье. Если длина вектора X меньше n, то недостающие элементы заполняются нулями. Если длина X больше п, то лишние элементы удаляются. Когда X — матрица, длина столбцов корректируется аналогично;
fft(X,[ Ldirn) и fft(X,n,dim) — применяют преобразование Фурье к одной из размерностей массива в зависимости от значения параметра dim.
Для иллюстрации применения преобразования Фурье создадим трехчастотный сигнал на фоне сильного шума, создаваемого генератором случайных чисел:
»t=0:0.0005:1:
»x=sin(2*pi*200*t)+0.4*sin(2*pi*150*t)
+0.4*sin(2*pi*250*t):
» y=x+2*randn(size(t));
» plot(y(l:100).'b')

Рис. 17.6. Форма зашумленного сигнала
Этот сигнал имеет среднюю частоту 200 рад/с и два боковых сигнала с частотами 150 и 250 рад/с, что соответствует амплитудно-модулированному сигналу с частотой модуляции 50 рад/с и глубиной модуляции 0.8 (амплитуда боковых частот составляет 0.4 от амплитуды центрального сигнала). На рис. 17.6 показан график этого сигнала (по первым 100 отсчетам из 2000). Нетрудно заметить, что из него никоим образом не видно, что полезный сигнал — амплитудно-модулированное колебание, настолько оно забито шумами. Теперь построим график спектральной плотности полученного сигнала с помощью прямого преобразования Фурье, по существу переводящего временное представление сигнала в частотное. Этот график в области частот до 300 Гц (см. рис. 17.6) строится с помощью следующих команд:
» Y=fft(y,1024):
» Pyy=*Y.*conj(Y)/1024;
» f=2000*(0:150)/1024;
» plot(f.Pyy(l:151)).grid
График спектральной плотности сигнала, построенный в этом примере, представлен на рис. 17.7. Даже беглого взгляда на рисунок достаточно, чтобы убедиться в том, что спектрограмма сигнала имеет явный пик на средней частоте амплитудно-модулированного сигнала и два боковых пика. Все эти три частотные составляющие сигнала явно выделяются на общем шумовом фоне. Таким образом, данный пример наглядно иллюстрирует технику обнаружения слабых сигналов на фоне шумов, лежащую в основе работы радиоприемных устройств.
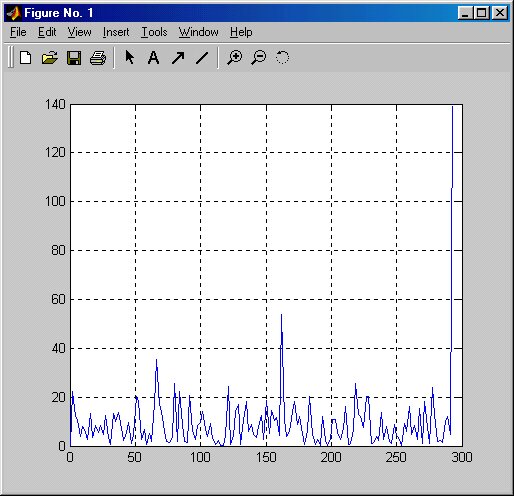
Рис. 17.7. График спектральной плотности приведенного на рис. 17.6 сигнала
Функции многомерного прямого преобразования Фурье
Для двумерного прямого преобразования Фурье используется функция fft2:
fft2(X) — возвращает для массива данных X двумерное дискретное преобразование Фурье;
fft2(X,m.n) — усекает массив X или дополняет его нулями, чтобы перед выполнением преобразования Фурье создать матрицу размера тхп. Результат — матрица того же размера.
Для многомерного прямого преобразования Фурье также существует функция:
fftn(X) — возвращает результат N-мерного дискретного преобразования для массива X размерности N. Если X — вектор, то выход будет иметь ту же ориентацию;
fftn(X.siz) — возвращает результат дискретного преобразования для массива X с ограничением размера, заданным переменной siz.
Функция Y = fftshift(X) перегруппировывает выходные массивы функций fft и fft2, размещая нулевую частоту в центре спектра, что иногда более удобно. Если X — вектор, то Y — вектор с циклической перестановкой правой и левой половин исходного вектора. Если X — матрица, то Y — матрица, у которой квадранты I и III меняются местами с квадрантами II и IV [Для одно- и двумерных массивов функция fftshift(X) эквивалентна функции rot90{X.2)]. Рассмотрим следующий пример. Вначале построим график спектральной плотности мощности (рис. 17.8) при одномерном преобразовании Фурье:
» rand('state'.0);
» WhO.001:0.512;
» x=sin(2*pi*50*t)+sin(2*pi*120*t);
» y=x+2*randn(size(t))+0.3;
» Y=fft(y);
» Pyy=Y.*conj(Y)/512:
» f=1000*(0:255)/512:

Рис. 17.8. График спектральной плотности сигнала после одномерного преобразования Фурье
Здесь мы ограничились 512 отсчетами, с тем чтобы использовать эффективны!: метод быстрого преобразования Фурье, при котором число отсчетов должно быт: 2N, где N - целое число. Теперь воспользуемся функцией fftshift:
» Y=fftshift(Y);
» Pyy=Y.*conj(Y)/512;
» p1ot(Pyy).grid
Полученный при этом график представлен на рис. 17.9.

Рис. 17.9. График спектральной плотности того же сигнала после применения функции fftshift
Надо отметить, что этот график дает значения спектральной плотности составляющих спектра не явно от частоты, а как распределение ее значений для элементов вектора Руу.
Функции обратного преобразования Фурье
Возможно одномерное обратное преобразование Фурье, реализуемое следующими функциями:
ifft(F) — возвращает результат дискретного обратного преобразования Фурье вектора F. Если F — матрица, то if ft возвращает обратное преобразование Фурье для каждого столбца этой матрицы;
ifft(F.n) — возвращает результат n-точечного дискретного обратного преобразования Фурье вектора F;
ifft(F.[ ],dim) иу = ifft(X,n,dim) — возвращают результат обратного дискретного преобразования Фурье массива F по строкам или по столбцам в зависимости от значения скаляра dim.
Для любого X результат последовательного выполнения прямого и обратного преобразований Фурье ifft(fft(x)) равен X с точностью до погрешности округления. Если X — массив действительных чисел, ifft(fft(x)) может иметь малые мнимые части.
Пример:
» V=[l 1110000]:
» fft(V)
ans =
Columns 1 through 4
4.0000 1.0000 - 2.41421 0 1.0000 - 0.41421
Columns 5 through 8
0 1.0000 + 0.41421 0 1.0000 + 2.41421
» 1fft(fft(V))
ans =
l 1 1 1 0 0 0 0
Аналогичные функции есть для двумерного и многомерного случаев:
ifft2(F) — производит двумерное дискретное обратное преобразование Фурье для матрицы F;
ifft2(F,m,n) — производит обратное преобразование Фурье размерности тхп для матрицы F;
ifftn(F) — возвращает результат JV-мерного обратного дискретного преобразования Фурье для N-мерного массива F;
ifftn(F.siz) — возвращает результат обратного дискретного преобразования Фурье для массива F с ограничением размера, заданным вектором siz. Если любой элемент siz меньше, чем соответствующая размерность F, то массив F будет урезан до размерности siz.
Свертка и дискретная фильтрация
Функция свертки и обратная ей функция
В этом разделе рассмотрены базовые средства для проведения операций свертки и фильтрации сигналов на базе алгоритмов быстрого преобразования Фурье. Многие дополнительные операции, относящиеся к этой области обработки сигналов, можно найти в пакете прикладных программ Signal Processing Toolbox.
Для двух векторов х и у с длиной тип определена операция свертки:
В ее результате получается вектор z с длиной (т+п- 1). Для осуществления свертки используется функция conv(x.y).
Обратная свертке функция определена как [q,r]=deconv(z,x). Она фактически определяет импульсную характеристику фильтра. Если z=conv(x,y), то q=y и г=0. Если х и у — векторы с коэффициентами полиномов, то свертка эквивалентна перемножению полиномов, а обратная операция — их делению. При этом вектор q возвращает частное (фактор), а вектор r - остаток от деления полиномов.
Функция свертки двумерных массивов
Для двумерных массивов также существует функция свертки: Z=conv2(X.Y) и Z=conv2(X,Y. 'option').
Для двумерных массивов X и Y с размером m хп и тхп соответственно результат двумерной свертки порождает массив размера (т +т -1)х(m +п -1). Во второй форме функции параметр option может иметь следующие значения:
' full' — полноразмерная свертка (используется по умолчанию);
'same' — центральная часть размера тхп ;
'valid' — центральная часть размера (т-т +1)х(п-п +1), еслн (тхпх)>(тхп ).
Возможность изменить решение или трактовку данных с помощью параметров является свойством ряда функций системы MATLAB. Позже мы столкнемся с этой возможностью еще не раз.
Дискретная одномерная фильтрация
MATLAB может использоваться для моделирования работы цифровых фильтров. Для обеспечения дискретной одномерной фильтрации используется функция filter в следующих формах записи:
filter(B.A.X) — фильтрует одномерный массив данных X, используя дискретный фильтр, описываемый следующим конечноразностным уравнением:
a(l)*y(n) = b(1)*x(n) + b(2)*х(п-1) + ... + b(nb+l)*x(n-nb) -- а(2)*у(п-1) - ... - a(na+l)*y(n-na).
Если а(1) не равно 1, то коэффициенты уравнения нормализуются относительно а (1). Когда X — матрица, функция filten оперирует столбцами X. Возможна фильтрация многомерного (размерности N) массива.
[Y. Zf]=fi 1 ten(В, A. X, Zi) — выполняет фильтрацию с учетом ненулевого начального состояния фильтра Zi; возвращает помимо выходного сигнала Y конечное состояние фильтра Zf;
filter(B.A.X,[ ].dim) или fi!ter(B.A,X.Zi .dim) — работает в направлении размерности dim
Рассмотрим типовой пример фильтрации гармонического сигнала на фоне других сигналов — файл с именем filtdem.m из пакета расширения Signal Processing Toolbox.
Следующий кадр иллюстрирует конструирование фильтра с достаточно плоской вершиной амплитудно-частотной характеристики (АЧХ) и полосой частот, обеспечивающего выделение сигнала с частотой 15 Гц и подавление сигналов с частотами 5 и 30 Гц. Для формирования полосы пропускания фильтра используется функция el 11 р, а для построения АЧХ — функция freqz (обе — из пакета Signal Processing Toolbox). Это позволяет построить график АЧХ созданного фильтра.
Следующий кадр примера иллюстрирует эффективность выделения сигнала заданной частоты (15 Гц) с помощью операции фильтрации — функции filter, описанной выше. Можно заметить два обстоятельства — полученный стационарный сигнал практически синусоидален, что свидетельствует о высокой степени фильтрации побочных сигналов. Однако нарастание сигнала во времени идет достаточно медленно и занимает несколько периодов частоты полезного сигнала. Характер нарастания сигнала во времени определяется переходной характеристикой фильтра.
Заключительный кадр показывает спектр исходного сигнала и спектр сигнала на выходе фильтра (он показан линиями другого цвета, что, к сожалению, не видно на черно-белом рисунке). Для построения спектров используется прямое преобразование Фурье — функция fft.
Этот пример наглядно иллюстрирует технику фильтрации. Рекомендуется просмотреть дополнительные примеры, которые есть в разделе Demos системы применительно к пакету расширения Signal Processing (если этот пакет установлен).
Для осуществления двумерной фильтрации служит функция filter2:
filter2(B.X) — фильтрует данные в двумерном массиве X, используя дискретный фильтр, описанный матрицей В. Результат Y имеет те же размеры, что и X;
filter2(B,X, 'option') — выполняет то же, но с опцией, влияющей на размер массива Y:
'same' — size(Y)=size(X) (действует по умолчанию);
'valid' — size(Y) < size(X), центральная часть двумерной свертки, при вычислении которой не приходится дополнять массивы нулями;
'full' — size(Y) > size(X), полная двумерная свертка.
Функция коррекции фазовых углов unwrap
Фазовые углы одномерных массивов испытывают разрывы при переходе через значения, кратные р. Функции unwrap(P) и unwrap(P,cutoff) устраняют этот недостаток одномерного массива Р, дополняя значения углов в точках разрыва значениями ±2р. Если Р — двумерный массив, то данная функция применяется к столбцам. Параметр cutoff (по умолчанию равный р) позволят назначить любой критический угол в точках разрыва. Функция используется при построении фазочастотных характеристик (ФЧХ) фильтров. Поскольку они строятся редко, оставим за читателем изучение практического применения данной функции.
Интерполяция и аппроксимация данных
Под аппроксимацией обычно подразумевается описание некоторой, порой не заданной явно, зависимости или совокупности представляющих ее данных с помощью другой, обычно более простой или более единообразной зависимости. Часто данные находятся в виде отдельных узловых точек, координаты которых задаются таблицей данных.
Результат аппроксимации может не проходить через узловые точки. Напротив, задача интерполяции — найти данные в окрестности узловых точек. Для этого используются подходящие функции, значения которых в узловых точках совпадают с координатами этих точек. Например, при линейной интерполяции зависимости у(х) узловые точки соединяются друг с другом отрезками прямых и считается, что искомые промежуточные точки расположены на этих отрезках.
Для повышения точности интерполяции применяют параболы (квадратичная интерполяция) или полиномы более высокой степени (полиномиальная интерполяция). Для обработки данных MATLAB использует различные функции интерполяции и аппроксимации данных. Набор таких функций вместе с несколькими вспомогательными функциями описан в этом разделе.
Одна из наиболее известных аппроксимаций — полиномиальная. В системе MATLAB определены функции аппроксимации данных полиномами по методу наименьших квадратов — полиномиальной регрессии. Это выполняет функция, приведенная ниже:
polyfit(x.y.n) — возвращает вектор коэффициентов полинома р(х) степени п, который с наименьшей среднеквадратичной погрешностью аппроксимирует функцию у(х). Результатом является вектор-строка длиной n+1, содержащий коэффициенты полинома в порядке уменьшения степеней х и у равно n+1, то реализуется обычная полиномиальная аппроксимация, при которой график полинома точно проходит через узловые точки с координатами (х.у), хранящиеся в векторах х и у. В противном случае точного совпадения графика с узловыми точками не наблюдается;
[p.S] = polyflt(x.y.n) — возвращает коэффициенты полинома р и структуру S для использования вместе с функцией polyval с целью оценивания или предсказания погрешности;
[p.S] = polyf1t(x,y,n,mu) возвращает коэффициенты полинома р и структуру S для использования вместе с функцией polyval с целью оценивания или предска-зния погрешности, но так, что присходит центрирование (нормирование) и масштабирование х, xnorm = (х - mu(l))/mu(2), где mu(l) = mean(x) и mu(2) = std(x). Центрирование и масштабирование не только улучшают свойства степенного многочлена, получаемого при помощи polyval, но и значительно повышают качественные характеристики самого алгоритма аппроксимации.

Рис. 17.10. Пример использования функции polyfit
Пример (полиномиальная регрессия для функции s
» х=(-3:0.2:3)':
y=sin(x);
p=polyflt(x.y,3)
р =
-0.0953 0.0000 0.8651 -0.0000
»x=(-4:0.2:4)';y=sin(x);
» f=polyval(p,x);plot(x.y.'o',x,f)
Рис. 17.14, построенный в этом примере, дает наглядное представление о точности полиномиальной аппроксимации. Следует помнить, что она достаточно точна в небольших окрестностях от точки х = 0, но может иметь большие погрешности за их пределами или в промежутках между узловыми точками.
График аппроксимирующего полинома третьей степени на рис. 17.10 показан сплошной линией, а точки исходной зависимости обозначены кружками. К сожалению, при степени полинома свыше 5 погрешность полиномиальной регрессии (и аппроксимации) сильно возрастает и ее применение без центрирования и масштабирования становится рискованным. Обратите внимание на то, что при полиномиальной регрессии узловые точки не ложатся точно на график полинома, поскольку их приближение к нему является наилучшим в смысле минимального среднеквадратического отклонения. Об этом уже говорилось.
Интерполяция периодических функций рядом Фурье
Под интерполяцией обычно подразумевают вычисление значений функции f(x) в промежутках между узловыми точками. Линейная, квадратичная и полиномиальная интерполяция реализуются при полиномиальной аппроксимации. А вот для периодических (и особенно для гладких периодических) функций хорошие результаты может дать их интерполяция тригонометрическим рядом Фурье. Для этого используется следующая функция:
interpft(x.n) — возвращает вектор у, содержащий значения периодической функции, определенные в п равномерно расположенных точках. Если length(x)=rr; и х имеет интервал дискретизации dx, то интервал дискретизации для у составляет dy=dx*m/n, причем п не может быть меньше, чем т. Если X — матрица, interpft оперирует столбцами X, возвращая матрицу Y с таким же числом столбцов, как и у X, но с п строками. Функция y=interpft(x.n.dim) работает либо со строками, либо со столбцами в зависимости от значения параметра dim.

Рис. 17.11. Пример использования функции interpft
Пример:
» x=0:10:y-sin(x).^3:
» xl-0:0.1:10;yl-interpft(y,101);
» x2=0:0.01:10:y2-sin(x2).^3;
» plot(xl,yl, '--').hold on.plotCx.y. 'o' .x2.y2)
Рис. 17.11 иллюстрирует эффективность данного вида интерполяции на примере функции sin(x).^3, которая представляет собой сильно искаженную синусоиду.
Исходная функция на рис. 17.12 представлена сплошной линией с кружками, а интерполирующая функция — штрих-пунктирной линией.
Интерполяция на неравномерной сетке
Для интерполяции на неравномерной сетке используется функция griddata:
ZI = griddata(x.y.z.XI.YI) — преобразует поверхность вида z = f(x. у), которая определяется векторами (x.y.z) с (обычно) неравномерно распределенными элементами. Функция griddata аппроксимирует эту поверхность в точках, определенных векторами (XI.YI) в виде значений ZI. Поверхность всегда проходит через заданные точки. XI и YI обычно формируют однородную сетку (созданную с помощью функции meshgrid).
XI может быть вектором-строкой, в этом случае он определяет матрицу с постоянными столбцами. Точно так же YI может быть вектором-столбцом, тогда он определяет матрицу с постоянными строками.
[XI.YI.ZI] = griddata(x,y,z,xi ,yi ) — возвращает аппроксимирующую матрицу ZI, как описано выше, а также возвращает матрицы XI и YI, сформированные из вектора-столбца xi и вектора-строки yi . Последние аналогичны матрицам, возвращаемым функцией meshgrid;
[...] = griddata (....method) — использует определенный метод интерполяции:
'nearest' — ступенчатая интерполяция;
'linear' — линейная интерполяция (принята по умолчанию);
'cubic' — кубическая интерполяция;
' v4 ' — метод, используемый в МATLAB 4.
Метод определяет тип аппроксимирующей поверхности. Метод 'cubic1 формирует гладкие поверхности, в то время как 'linear' и 'nearest' имеют разрывы первых и нулевых производных соответственно. Все методы, за исключением v4, основаны на триангуляции Делоне. Метод ' v4 ' включен для обеспечения совместимости с версией 4 системы MATLAB. Пример:
» x=rand(120.1)*4-2;y=rand(120.1)*4-2;
z=x.*y.*exp(-x.^2-y.^2);
» t=-2:0.1:2:[X,Y]=meshgrid(t,t);
Z=griddata(x.y.z.X.Y):
» mesh(X.Y.Z).hold on.plot3(x.y,z, 'ok')
Функции griddataS и griddatan работают аналогично griddata, но для для трехмерного и n-мерного случая — с использованием алгоритма qhul 1 . Используются, в частности, при трехмерной и n-мерной триангуляции.
Рис. 17.13 иллюстрирует применение функции griddata.

Рис 17.12. Пример использования функции griddata
Одномерная табличная интерполяция
В ряде случаев очень удобна сплайновая интерполяция и аппроксимация таблично заданных функций. При ней промежуточные точки ищутся по отрезкам полиномов третьей степени — это кубическая сплайновая интерполяция. При этом обычно такие полиномы вычисляются так, чтобы не только их значения совпадали с координатами узловых точек, но также чтобы в узловых точках были непрерывны производные первого и второго порядков. Такое поведение характерно для гибкой линейки, закрепленной в узловых точках, откуда и происходит название spline (сплайн) для этого вида интерполяции (аппроксимации). Для одномерной табличной интерполяции используется функция interpl:
yi = Interpl(x.Y.xi) — возвращает вектор yi, содержащий элементы, соответствующие элементам xi и полученные интерполяцией векторов х и Y. Вектор х определяет точки, в которых задано значение Y. Если Y — матрица, то интерполяция выполняется для каждого столбца Y и у1 имеет длину length (xi) - by- size (Y. 2);
yi = interpl (x.Y.xi .method) — позволяет с помощью параметра method задать метод интерполяции:
'nearest' — ступенчатая интерполяция;
'linear' — линейная интерполяция (принята по умолчанию);
'spline' — кубическая сплайн-интерполяция;
'cubic' или 'pchip' — интерполяция многочленами Эрмита;
'v5cubic' — кубическая интерполяция MATLAB 5.
yi = interpl (x.Y.xi .method, значение величин вне пределов изменения х) —позволяет отобразить особенные точки на графике;
yi = i nterpl(х, Y, xi.method.' сообщение') — позволяет изменить сообщение об особенных точках на графике.
Все методы интерполяции требуют, чтобы значения х изменялись монотонно. Когда х — вектор равномерно распределенных точек, для более быстрой интерполяции лучше использовать методы '*1inear', '*cubic', '*nearest' или '*spline'. Обратите внимание, что в данном случае наименованию метода предшествует знак звездочки.
Пример (интерполяция функции косинуса):
» x=0:10:y=cos(x);
» xi=0:0.1:10:
» yi=interpl(x.y.xi);
» plot(x,y.'x',xi,yi,'g'),hold on
» yi=interpl(x,y.xi.'spline'):
» plot(x.y,'o',xi,yi,'m').grid,hold off
Узловые точки на рис. 17.17 обозначены кружками с наклонными крестиками. Одна из кривых соответствует линейной интерполяции, другая — сплайн-интерполяции. Нетрудно заметить, что сплайн-интерполяция в данном случае дает гораздо лучшие результаты, чем линейная интерполяция. При последней точки просто соединяются друг с другом отрезками прямых, так что график интерполирующей кривой при линейной интерполяции получается негладким.
Двумерная табличная интерполяция
Двумерная интерполяция существенно сложнее, чем одномерная, рассмотренная выше, хотя смысл ее тот же — найти промежуточные точки некоторой зависимости z(x, у) вблизи расположенных в пространстве узловых точек. Для двумерной табличной интерполяции используется функция interp2:
ZI = interp2(X,Y.Z,XI.YI) — возвращает матрицу ZI, содержащую значения функции в точках, заданных аргументами XI и YI, полученные путем интерполяции двумерной зависимости, заданной матрицами X, Y и Z. При этом X и Y должны быть монотонными и иметь тот же формат, как если бы они были получены с помощью функции meshgrid (строки матрицы X являются идентичными; то же можно сказать о столбцах массива Y). Матрицы X и Y определяют точки, в которых задано значение Z. Параметры XI и YI могут быть матрицами, в этом случае interp2 возвращает значения Z, соответствующие точкам (XI(i,j),YI(i.j)). В качестве альтернативы можно передать в качестве параметров вектор-строку xi и вектор-столбец yi. В этом случае interp2 представляет эти векторы так, как если бы использовалась команда mesh-grid(xi .yi);
ZI = interp2(Z,XJ.YI) — подразумевает, что Х=1:n и Y=l:m, где [m.n]=size(Z);
ZI = interp2(Z,ntimes) — осуществляет интерполяцию рекурсивным методом с числом шагов ntimes;
ZI = interp2(X,Y,Z.XI,YI.method) — позволяет с помощью опции method задать метод интерполяции:
'nearest' — интерполяция по соседним точкам;
'linear' — линейная интерполяция;
'cubic' — кубическая интерполяция (полиномами Эрмита);
'spline' — интерполяция сплайнами.
Все методы интерполяции требуют, чтобы X и Y изменялись монотонно и имели такой же формат, как если бы они были получены с помощью функции meshgrid. Когда X и Y — векторы равномерно распределенных точек, для более быстрой интерполяции лучше использовать методы '*1inear', '*cubic', или '*nearest'.
Пример:
» [X.Y]=meshgrid(-3:0.25:3);
Z=peaks(X/2.Y*2):
» [Xl,Yl]=meshgrid(-3:0.1:3);
Zl=interp2(X,Y.Z.Xl.Yl):
» mesh(X.Y,Z).hold on.mesh(Xl.Yl,Zl+15).hold off

Рис. 17.13. Применение функции interpZ
Рис. 17.13 иллюстрирует применение функции interp2 для двумерной интерполяции (на примере функции peaks).
В данном случае поверхность снизу — двумерная линейная интерполяция, которая реализуется по умолчанию, когда не указан параметр method.
Трехмерная табличная интерполяция
Для трехмерной табличной интерполяции используется функция interp3:
VI = interp3(X.Y.Z.V.XI,YI.ZI) — интерполирует, чтобы найти VI, значение основной трехмерной функции V в точках матриц XI, YI и ZI. Матрицы X, Y и Z определяют точки, в которых задано значение V. XI, YI и ZI могут быть матрицами, в этом случае InterpS возвращает значения Z, соответствующие точкам (XI (i ,j) ,YI(i. j), ZI (i. j)). В качестве альтернативы можно передать векторы xi, yl и zi. Векторы аргументы, имеющие неодинаковый размер, представляются, как если бы использовалась команда meshgrid;
VI = interp3(V.XI.YI.ZI) - подразумевает X=1:N, Y=1:M, Z=1:P, где [M,N.P]=size(V);
VI = interpS(V.ntimes) — осуществляет интерполяцию рекурсивным методом с числом шагов ntimes;
VI = interp3(... .method) — позволяет задать метод интерполяции:
'nearest' — ступенчатая интерполяция;
'linear' — линейная интерполяция;
'cubic' — кубическая интерполяция (полиномами Эрмита);
'spline' — интерполяция сплайнами.
Все методы интерполяции требуют, чтобы X, Y и Z изменялись монотонно и имели такой же формат, как если бы они были получены с помощью функции meshgrid. Когда X и Y и Z — векторы равномерно распределенных в пространстве узловых точек, для более быстрой интерполяции лучше использовать методы '*li'near', '*cubic' или '*nearest'.
N-мерная табличная интерполяция
MATLAB позволяет выполнить даже n-мерную табличную интерполяцию. Для этого используется функция interpn:
VI = interpn(Xl.X2,X3,... ,V,Y1.Y2.Y3....)- интерполирует, чтобы найти VI, значение основной многомерной функции V в точках массивов Yl, Y2, Y3,.... Функции interpn должно передаваться 2ЛГ+1 аргументов, где N — размерность интерполируемой функции. Массивы XI, Х2, ХЗ,... определяют точки, в которых задано значение V. Параметры Yl, Y2, Y3,... могут быть матрицами, в этом случае interpn возвращает значения VI, соответствующие точкам (YKi, j) ,Y2(i, j), Y3(i, j),...). В качестве альтернативы можно передать векторы yl, y2, уЗ,... В этом случае interpn интерпретирует их, как если бы использовалась команда ndgrid(yl. У2.у3....);
VI = interpn(V.Yl,Y2,Y3,...) - подразумевает Xl=1size(V.l), X2=l:size(V,2), X3=l:size(V,3) и т. д.;
VI = Interpn(V.ntimes) — осуществляет интерполяцию рекурсивным методом с числом шагов ntimes;
VI = interpn(...method) — позволяет указать метод интерполяции:
'nearest' — ступенчатая интерполяция;
'linear' — линейная интерполяция;
'cubic' — кубическая интерполяция.
В связи с редким применением такого вида интерполяции, наглядная трактовка которой отсутствует, примеры ее использования не приводятся.
Интерполяция кубическим сплайном
Сплайн-интерполяция используется для представления данных отрезками полиномов невысокой степени — чаще всего третьей. При этом кубическая интерполяция обеспечивает непрерывность первой и второй производных результата интерполяции в узловых точках. Из этого вытекают следующие свойства кубической сплайн-интерполяции:
график кусочно-полиномиальной аппроксимирующей функции проходит точно через узловые точки;
в узловых точках нет разрывов и резких перегибов функции;
благодаря низкой степени полиномов погрешность между узловыми точками обычно достаточно мала;
связь между числом узловых точек и степенью полинома отсутствует;
поскольку используется множество полиномов, появляется возможность аппроксимации функций с множеством пиков и впадин.
Как отмечалось, в переводе spline означает «гибкая линейка». График интерполирующей функции при этом виде интерполяции можно уподобить кривой, по которой изгибается гибкая линейка, закрепленная в узловых точках. Реализуется сплайн-интерполяция следующей функцией:
yi = spline(x,y,xi) — использует векторы х и у, содержащие аргументы функции и ее значения, и вектор xi, задающий новые точки; для нахождения элементов вектора yi используется кубическая сплайн-интерполяция;
рр = spline(x.y) — возвращает рр-форму сплайна, используемую в функции ppval и других сплайн-функциях.
Пример:
» х=0:10: y=3*cos(x);
» xl=0:0.1:11;
» y1=spline(x,y.xl);
» plot(x.y,'о'.xl.yl.'--')
Сплайн-интерполяция дает неплохие результаты для функций, не имеющих разрывов и резких перегибов. Особенно хорошие результаты получаются для монотонных функций.
Результат интерполяции показан на рис. 17.14.

Рис. 17.14. Пример применения функции spline
Ввиду важности сплайн-интерполяции и аппроксимации в обработке и представлении сложных данных в состав системы MATLAB входит пакет расширения Spline Toolbox, содержащий около 70 дополнительных функций, относящихся к реализации сплайн-интерполяции и аппроксимации, а также графического представления сплайнами их результатов. Для вызова данных об этом пакете (если он установлен) используйте команду help splines.
Обработка данных в графическом окне
Средства обработки данных в графическом окне
Решение большинства задач интерполяции и аппроксимации функций и табличных данных обычно сопровождается их визуализацией. Она, как правило, заключается в построении узловых точек функции (или табличных данных) и в построении функции аппроксимации или интерполяции. Для простых видов аппроксимации, например полиномиальной, желательно нанесение на график формулы, полученной для аппроксимации.
В MATLAB 6,0 совмещение функций аппроксимации с графической визуализацией доведено до логического конца — предусмотрена аппроксимация рядом методов точек функции, график которой построен. И все это выполняется прямо в окне редактора графики Property Editor. Для этого в позиции Tools графического окна имеются две новые команды:
Basic Fitting - основные виды аппроксимации (регрессии);
Data Statistics - статистические параметры данных.
Команда Basic Fitting открывает окно, дающее доступ к ряду видов аппроксима-- ции и регрессии: сплайновой, эрмитовой и полиномиальной со степенями от 1 (линейная аппроксимация) до 10. В том числе со степенью 2 (квадратичная аппроксимация) и 3 (кубическая аппроксимация). Команда Data Statistics открывает окно с результатами простейшей статистической обработки данных.
Полиномиальная регрессия для табличных данных
Рассмотрим самый характерный пример обработки данных, примерно представляющих некоторую (например, экспериментальную) зависимость вида у(х). Пусть она задана в табличной форме, причем колонки таблицы соответствуют элементам векторов X и Y одинакового размера в следующем примере:
» Х=[2.4,6.8.10.12.14];
» Y=[3.76.4.4.5.1.5.56.6.6.3.6.7];
» plot(X.Y.'o');
Напомним, что последняя команда строит график узловых точек кружками (без соединения их отрезками прямых).
Рис. 17.15 показывает пример выполнения полиномиальной регрессии (аппроксимации) для степеней полинома 1, 2 и 3 (дальнейшее повышение степени полинома в данном случае уже лишено смысла, поскольку графики полиномиальной регрессии со степенью выше 3 почти не различаются).

Рис. 17.15. Пример обработки табличных данных в графическом окне
Поясним, что же показано на рис. 17.20. В левом верхнем углу сессии MATLAB видна запись приведенных выше исходных векторов и команды построения заданных ими точек кружками. Справа показано большое окно графики с построенными в нем кружками узловыми точками.
![]() При проведении полиномиальной аппроксимации надо помнить, что максимальная степень полинома на 1 меньше числа точек, т. е. числа элементов в векторах X и Y.
При проведении полиномиальной аппроксимации надо помнить, что максимальная степень полинома на 1 меньше числа точек, т. е. числа элементов в векторах X и Y.
Исполнив команду Tools > Basic Fitting, можно получить окно регрессии. Оно показано на рис. 17.20 слева прямо под записью исходных команд в командной строке. В этом окне птичкой отмечены три вида полиномиальной регрессии — порядка 1 (linear — линейная), 2 (quadratic — квадратичная) и 3 (cubic — кубическая). Стоит отметить какой-либо вид регрессии, как соответствующая кривая функции регрессии (аппроксимации) появится в графическом окне.
Установив птичку у параметра Show equations (Показать уравнения), можно получить в графическом окне запись уравнений регрессии (аппроксимации). Наконец, можно сместить выводимую по умолчанию легенду в место, где она не закрывала бы другие детали графика.
Наконец, исполнив команду Tools > Data Statistics, можно получить окно с рядом статистических параметров данных, представленных векторами X и Y. Отметив птичкой тот или иной параметр в этом окне (оно показано на рис. 17.20 под окном графики), можно наблюдать соответствующие построения на графике, например вертикалей с минимальным, средним и максимальных значением у и горизонталей с минимальным, средним и максимальным значением х.
![]() Безусловно, эта новинка понравится большинству пользователей системы MATLAB 6.0. Однако нельзя не отметить, что статистические данные более чем скупы.
Безусловно, эта новинка понравится большинству пользователей системы MATLAB 6.0. Однако нельзя не отметить, что статистические данные более чем скупы.
Оценка погрешности аппроксимации
Средства обработки данных из графического окна позволяют строить столбцовый или линейчатый график погрешностей в узловых точках и наносить на эти графики норму погрешности. Норма дает статистическую оценку среднеквадрати-ческой погрешности. Чем она меньше, тем точнее аппроксимация. Для вывода графика погрешности надо установить птичку у параметра Plot residuals (График погрешностей) и в меню ниже этого параметра выбрать тип графика.
Таким образом, интерфейс графического окна позволяет выполнять эффективную обработку данных наиболее распространенными способами.
Сплайновая интерполяция в графическом окне
Попытка аппроксимации полиномом 8-й степени не дает положительного результата — кривая проходит внутри облака точек, совершенно не интерполируя это облако.
Однако если применить сплайновую интерполяцию, то картина кардинально меняется. На этот раз кусочная линия интерполяции прекрасно проходит через все точки и поразительно напоминает синусоиду. Даже ее пики со значениями 1 и -1 воспроизводятся удивительно точно, причем и в случаях, когда на них не попадают узловые точки.
Причина столь великолепного результата кроется в уже отмеченных ранее особенностях сплайновой интерполяции - она выполняется по трем ближайшим
точкам, причем эти тройки точек постепенно перемещаются от начала точечного графика функции к ее концу. Кроме того, непрерывность первой и второй производных при сплайновой интерполяции делает кривую очень плавной, что характерно и для первичной функции — синусоиды. Так что данный пример просто является удачным случаем применения сплайновой интерполяции.

Рис. 17.16. Пример сплайновой интерполяции в графическом окне
Мы не можем практически называть этот подход полноценной аппроксимацией, поскольку в данном случае нет единого выражения для аппроксимирующей функции. На каждом отрезке приближения используется кубический полином с новыми коэффициентами. Поэтому и вывода аппроксимирующей функции в поле графика не предусмотрено.
Эрмитовая многоинтервальная интерполяция
MATLAB 6.0 дает возможность в графическом окне использовать еще один вид многоинтервальной интерполяции на основе полиномов третьей степени Эрмита. Техника интерполяции здесь таже, что и в случае сплайновой интерполяции, (рис. 17.17).
Полиномы Эрмита имеют более гибкие линии, чем сплайны. Они точнее следуют за отдельными изгибами исходной зависимости. Это хорошо показывает рис. 17.17.

Рис. 17.17. Пример эрмитовой интерполяции синусойды в графическом окне
Сравнение сплайновой и эрмитовой интерполяции
Оба вида интерполяции в данном случае дают превосходные результаты, поскольку представляемая ими кусочная функция практически почти точно проходит через все заданные точки. Однако если учесть, что эти точки принадлежат синусоиде, то в данном случае результаты сплайновой интерполяции оказываются явно лучшими. Особенно это характерно для экстремальных точек.
Поскольку в этих двух методах интерполяции кривая интерполяции проходит точно через узловые точки, в этих точках погрешности интерполяции равны нулю. Вы можете проверить это задав вывод графика погрешности. В целом, можно заключить, что сплайновая интерполяция лучше, когда нужно эффективное сглаживание быстро меняющихся от точки к точке данных и когда исходная зависимость описывается линиями, которые мы наблюдаем при построении их с помощью гибкой линейки. Эрмитова интерполяция лучше отслеживает быстрые изменения исходных данных, но имеет худшие сглаживающие свойства.
Все это говорит о том, что надо внимательно подходить к оценке приемлемости того или иного вида интерполяции (или аппроксимации) для конкретных типов исходных данных.
В этом уроке мы научились:
Выполнять статистическую обработку элементов массивов.
Осуществлять триангуляцию и строить диаграммы Вороного.
Осуществлять прямое и обратное преобразование Фурье.
Осуществлять аппроксимацию и интерполяцию данных.
Вести обработку данных в графических окнах.